Лекция 16
Сервисы сетевых операционных систем SQL –сервер
СУБД SQL Server появилась в 1989 году и с тех пор значительно изменилась. Огромные изменения претерпели масштабируемость продукта, его целостность, удобство администрирования, производительность и функциональные возможности.
Microsoft SQL Server – это реляционная система управления базой данных (СУБД). В реляционных базах данных данные хранятся в таблицах.
Взаимосвязанные данные могут группироваться в таблицы, кроме того, могут быть установлены также и взаимоотношения между таблицами. Отсюда и произошло название реляционные – от английского слова relational (родственный, связанный отношениями, взаимозависимый). Пользователи получают доступ к данным на сервере через приложения, а администраторы, выполняя задачи конфигурирования, администрирования и поддержки базы данных, производят непосредственный доступ к серверу.
SQL Server является масштабируемой базой данных, это значит, что она может хранить значительные объемы данных и поддерживать работу многих пользователей, осуществляющих одновременный доступ к базе данных.
В данной лекции мы рассмотрим два типа окружений, в которых можно использовать SQL Server.
Системы SQL Server
Система SQL Server может быть реализована либо как клиент-серверная система, либо как автономная "настольная" система. Тип проектируемой вами системы зависит от количества пользователей, которые должны одновременно осуществлять доступ к базе данных, и от характера работ, которые должны выполняться. В этом разделе мы рассмотрим оба типа систем SQL Server.
Клиент-серверная система SQL Server
Клиент-серверная система SQL Server может иметь двухзвенную установку (two-tier setup) либо трехзвенную установку (three-tiersetup). Независимо от варианта установки, программное обеспечение и базы данных SQL Server размещаются на центральном компьютере, который называется сервер базы данных (database server). Пользователи работают на отдельных компьютерах, которые называются клиенты (clients). Доступ пользователей к серверу базы данных производится при помощи приложений с их компьютеров-клиентов (в двухзвенных системах) либо при помощи приложений, выполняющихся на специально предназначенном для этой цели компьютере, который называется сервер приложений (application server) (в трехзвенных системах).
В частности, в двухзвенных системах клиенты исполняют приложения, осуществляющие доступ к серверу базы данных непосредственно через сеть.
Таким образом, компьютеры-клиенты исполняют программный код, соответствующий нуждам предприятия, и код, отображающий для пользователя результаты доступа к базе данных. Такие клиенты называются толстыми (thick client), потому что они выполняют два вида работы (cм. рис. 1).
Двухзвенная установка полезна при относительно небольшом количестве пользователей, потому что для соединения с каждым из пользователей расходуются системные ресурсы, такие как память и блокировки (locks). Чем больше будет количество соединений с пользователями, тем хуже будет производительность системы, из-за соперничества за ресурсы. В этих условиях вас может заинтересовать применение трехзвенной системы.
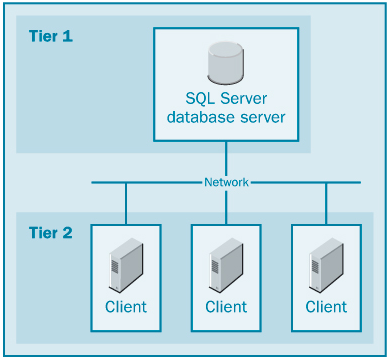
Рис. 1. Двухзвенная клиент-серверная система
Как уже говорилось ранее, в трехзвенной установке имеется третий компьютер, который называется сервер приложений. В системах этого типа в задачи компьютеров-клиентов входит лишь исполнение программного кода по вызову функций с сервера приложений и отображение результатов доступа. Такие клиенты называются тонкими (thin client). Cервер приложений исполняет приложения, которые выполняют задачи, требующиеся для нужд предприятия, эти приложения являются многопотоковыми (multithreaded), благодаря чему с ними могут работать много пользователей одновременно. Cервер приложений соединяется с сервером базы данных, осуществляет доступ к данным и возвращает результаты клиенту (см. рис. 2).
Достоинством трехзвенной системы является то, что можно позволить серверу приложений организовывать все клиентские соединения с сервером базы данных, вместо того, чтобы разрешить каждому клиенту самостоятельно устанавливать соединения (такая самостоятельность может привести к нерациональному использованию ресурсов сервера базы данных). Этот подход называется организация пула соединений (connection pooling), при этом предполагается, что запросы клиентов помещаются в пул (или, говоря точно, в очередь, queue), в котором они будут дожидаться ближайшего доступного соединения. Сразу же по освобождении соединения, оно может использоваться для нужд следующего запроса из очереди. Организация пулов соединений позволяет в некоторой степени регулировать объем работы, выполняемой сервером базы данных, конфигурируя количество соединений, имеющихся в пуле и, следовательно, количество соединений, доступных для выполнения задач пользователей (количество соединений можно конфигурировать программно). Так можно избавиться от потребности в большом количестве пользовательских соединений, способных быстро израсходовать ресурсы и замедлить скорость работы. Организация пулов соединений может быть реализована при помощи Internet Information Server (продукта фирмы Microsoft) и программного обеспечения для организации пулов соединений, вроде COM+.
Для некоторых корпоративных систем и веб-сайтов требуется большая производительность, чем способен обеспечить один сервер. SQL Server обладает способностью разделять таблицы по нескольким серверам, благодаря чему можно распределить нагрузку по обработке данных.

Рис. 2. Трехзвенная клиент-серверная система
Настольная система
SQL Server может использоваться также и как автономный (stand-alone) сервер базы данных, работающий на настольном или на портативном компьютере. Называются такие конфигурации настольными системами (desktop system). В них клиентские приложения исполняются на том же компьютере, на котором хранится программное обеспечение, реализующее механизм работы SQL Server и базы данных. В данной системе применяется только один компьютер, поэтому не устанавливаются никакие сетевые соединения от клиента к серверу – клиент устанавливает локальное соединение со своей локальной установкой SQL Server.
Настольные системы полезны при доступе к базе данных лишь одного пользователя или при небольшом числе пользователей, работающих с базой данных совместно (не одновременно). Настольные системы можно применять, например, в небольшом магазине, в котором имеется только один компьютер, а база данных – небольшая).
Обзор Microsoft SQL SERVER 2012
C выходом SQL Server 2012 (ранее «Denali») разработчики располагают более удобными средствами создания приложений для работы с базами данных. Обновления, с одной стороны, позволили расширить круг решаемых задач, а с другой, добиться более производительной работы существующих решений. Администраторы баз данных смогут без особых усилий достичь требуемой надежности и безопасности информации. Кроме того, возросла степень защищенности хранимых на сервере данных. Бизнес-аналитики смогли оценить возможности нового аналитического механизма, который был предложен специалистами MS еще в SQL Server 2008 R2 в виде PowerPivot на стороне клиента (в Excel 2010) и на серверной стороне SharePoint 2010.
Установка и обновление.
Старые версии SQL Server (2005, 2008 и 2008 R2) могут быть обновлены до новой версии SQL Server с рабочим названием Denali.
DATABASE ENGINE
Высокая доступность и восстановление после сбоев.
«Джуно» (Juneau)
Juneau — кодовое имя нового набора инструментов разработки для SQL Server. Цель проекта – реализация единой среды для выполнения всех действий, связанных с разработкой баз данных. Одной из задач Juneau является объединение BIDS (Business Intelligence Development Studio) и SSMS (SQL Server Management Studio) в интегрированную среду разработки.
SQL Server Developer Tools - расширение возможностей Visual Studio по работе с БД.
SHAREPOINT
Чтобы настроить ферму серверов с использованием возможностей Denali, к Sharepoint 2010 должен быть применен пакет обновлений SP1.
BIDS
С выходом новой версии SQL Server, BIDS основано на платформе Visual Studio 2010.
Reporting Services
SSRS: интеграция с PowerPoint; создание отчетов в веб-браузере, галерея отчетов с предварительными изображениями, слайсеры как в Excel. Project Crescent предоставляет возможность интуитивного создания специализированных отчетов для бизнес-аналитиков. Пользователи могут легко создавать и работать с представлениями данных из табличных моделей, основанных на книгах PowerPivot, опубликованных в галерее PowerPivot, а также табличных моделей, развернутых на сервере аналитики SQL Server. Project Crescent – это браузерно-ориентированное SilverLight – приложение, запускаемое из Sharepoint 2010.
Сервер аналитики (SSAS)
В SQL Server Denali появился новой режим работы сервера аналитики – табличный (tabular mode). Во время установки допускается выбор либо табличного режима, либо многомерного режима. Табличные модели можно будет создавать в новой версии BIDS, созданные на платформе Visual Studio 2010. Табличные модели могут основываться на базе PowerPivot книг.
Табличные модели – это базы данных сервера аналитики, выполняю-щихся в оперативной памяти. Используя алгоритмы шифрования и многопоточные запросы процессора, VertiPaq обеспечивает быстрый доступ к объектам табличных моделей.
Табличные модели поддерживают доступ к данным в двух режимах: режим кэширования и DirectQuery режим. В режиме кэширования можно интегрировать данные из нескольких источников, включая реляционные базы данных, каналы данных и плоские текстовые файлов. В DirectQuery режиме, вы можете обойти in-memory модели, что позволяет клиентским приложениям запрашивать данные непосредственно в (SQL Server реляционных) источника.
Табличные модели можно создать в Business Intelligence Development Studio с использованием новых шаблонов проектов табличной модели. Вы можете импортировать данные из нескольких источников, а затем обогащать модель, добавив отношения, вычисляемые столбцы, меры, ключевые индикаторы производительности и иерархии. Модели могут быть развернуты на экземпляре служб Analysis Services, где клиентские приложения отчетности могут подключаться к ним. Развернутыми моделями можно управлять в SQL Server Management Studio, как многомерными моделями.
Основным нововведением в SSAS является модель данных, называемая Business Intelligence Semantic Model (BISM). Вот некоторые детали:
• Она включает реляционную (также называемую табличную) модель данных и объединяет ее вместе с многомерной модели (OLAP) в еди-ную платформу бизнес-аналитики под названием Business Intelligence Semantic Model;
• Семантическая модель может являться одним источником данных для отчетности, аналитики, панелей мониторинга, систем показателей и пользовательских приложений. Все клиентские средства из стека Microsoft BI (Excel, PowerPivot, SharePoint Insights and Reporting Services (including Crescent) могут оперировать с этой моделью;
• Модель может быть общей для всех средств, что позволяет переходить с одного инструмента на другой. Например, книги PowerPivot, построенные бизнес-пользователями, могут быть использованы в качестве отправной точки BI- профессионалами для построения приложения Analysis Services;
• Для уже существующих кубов Analysis Services (также известных как UDM) – когда вы производите апгрейд вашего проекта Analysis Services или сервера до Denali, каждый куб автоматически становится семантической моделью;
Семантическая модель является результатом эволюции от чистой многомерной модели к гибридной. Гибридная модель предлагаем все возможности UDM и многое другое.
• Таким образом, термин UDM больше не используется с SQL Server Denali;
• Семантическая модель BISM позволяет достичь более широкой пользовательской базы, потому что табличная модель данных эквивалентна представлению источника данных, который создается при использовании многомерной модели. Но вам не нужно строить структуру куба.
Концепция BISM может быть представлена в виде трехуровневой модели:
Многомерное моделирование (концепция моделирования данных как кубы, измерения и иерархии) будет лучше для определенных типов BI приложений, таких как финансовые приложения со сложными расчетами, в которых производится бюджетирование, планирование и прогнозирование.
Табличная модель использует VertiPaq, значения хранятся в оперативной памяти, поиск данных и расчеты происходят быстро, т.к. дисковые операции ввода / вывода опускаются.
Семантическая модель (BISM) заменяет Унифицированную многомерную модель (UDM), но поддерживает существующие многомерные модели и новую табличную модель.